
谷歌最强模型Gemini 2.5上线,OpenAI又火速推出4o图像生成功能

这个Gemini 2.5被称为"会思考的模型",它的特别之处在于不会急着回答问题,而是先在"脑子里"好好想一想,所以答案更准、表现更棒!不过,我们测试后发现,提示词Gemini 2.5 Pro编码能力测试显示,整体动画细节比较好,但是画面丰富度没有Claude 3.7和DeepSeek-V3 0324好。
但是,就在谷歌发布消息时,OpenAI立即推出了超强的"OpenAI 4o图像生成功能"!OpenAI这次可是下了血本,他们的4o图像生成技术在细节表现、创意想象和生成速度上都实现了质的飞跃,完全碾压了谷歌的同类产品!
业内人士纷纷表示,OpenAI这次的图像生成功能升级不只是单纯的技术更新,更是向谷歌发起的全面挑战。OpenAI显然不甘落后,正集中全部火力与谷歌一较高下。这场AI巨头之间的"军备竞赛"可真是越来越精彩了,对我们用户来说,这种良性竞争带来的技术进步简直不要太爽!看来AI界的"卷王竞争"又进入了白热化阶段。
提示词: A wide image taken with a phone of a glass whiteboard, in a room overlooking the Bay Bridge. The field of view shows a woman writing, sporting a tshirt wiith a large OpenAI logo. The handwriting looks natural and a bit messy, and we see the photographer's reflection.
The text reads:
(left) "Transfer between Modalities:
Suppose we directly model p(text, pixels, sound) [equation] with one big autoregressive transformer.
Pros:
-
image generation augmented with vast world knowledge -
next-level text rendering -
native in-context learning -
unified post-training stack
Cons:
-
varying bit-rate across modalities -
compute not adaptive"
(Right) "Fixes:
-
model compressed representations -
compose autoregressive prior with a powerful decoder"
On the bottom right of the board, she draws a diagram: "tokens -> [transformer] -> [diffusion] -> pixels"


图像生成,变得更实用
从原始洞穴壁画到现代信息图,人类自古就善用图像来交流、说服和分析,而不仅仅是用来装饰。当今的生成模型虽然可以打造出超现实、令人惊艳的画面,但面对日常信息传递所需的基础图像,如徽标、图表等,仍显力不从心。事实上,当图像配合能唤起共同语言与经验的符号,它们就能传达极其精准的含义。
GPT-4o 图像生成能力在文本呈现、指令响应及上下文理解方面表现尤为出色,它可以调用自身庞大的知识库和对话上下文信息,甚至还能对上传的图像进行改造,或从中汲取灵感。这一切让你能更轻松地将想象变为图像,使视觉沟通更高效,也标志着图像生成迈向更实用、更精准、更强大的全新阶段。
一、图像中的文字表达
一张图能胜过千言万语,但恰到好处地加入几行文字,往往能为图像赋予更深层的含义。4o 精准融合图像与文字符号的能力,让图像生成成为真正意义上的视觉沟通工具。
提示词: Create a photorealistic image of two witches in their 20s (one ash balayage, one with long wavy auburn hair) reading a street sign.
Context: a city street in a random street in Williamsburg, NY with a pole covered entirely by numerous detailed street signs (e.g., street sweeping hours, parking permits required, vehicle classifications, towing rules), including few ridiculous signs at the middle: (paraphrase it to make these legitimate street signs)"Broom Parking for Witches Not Permitted in Zone C" and "Magic Carpet Loading and Unloading Only (15-Minute Limit)" and "Reindeer Parking by Permit Only (Dec 24–25)\n Violators will be placed on Naughty List." The signpost is on the right of a street. Do not repeat signs. Signs must be realistic.
Characters: one witch is holding a broom and the other has a rolled-up magic carpet. They are in the foreground, back slightly turned towards the camera and head slightly tilted as they scrutinize the signs.
Composition from background to foreground: streets + parked cars + buildings -> street sign -> witches. Characters must be closest to the camera taking the shot

提示词: photo of a delightful wedding invitation on a tasteful wooden desk. The card is hefty, with eggshell textures, and beautiful embossings, with elegant decorations abstractly representing the couple tastefully integrated into the designs. Iconography is used, but sparingly and in a minimalist way. perfect typesetting.
"You are cordially invited to the long-awaited union of Image and Text
After years of flirting and collaboration they are finally becoming One.
Together at last, in GPT‑4o, they now speak the same language — where a whisper becomes a masterpiece, and a prompt becomes a picture.
Please join us in celebrating this magical multimodal matrimony where imagination knows no bounds.
Date: March 25, 2025 Location: chatgpt.com Dress Code: Pixels or Prose
With love, OpenAI" perfect typesetting.

二、支持多轮对话的图像生成
图像生成已深度集成进 GPT‑4o,这意味着你可以像对话一样自然地迭代图像创作。GPT‑4o 能结合聊天中的图像和文字上下文,保持风格与内容的一致性。例如,当你在设计一款游戏角色时,角色的形象在多轮修改中依然连贯统一,让创作过程更加顺畅高效。
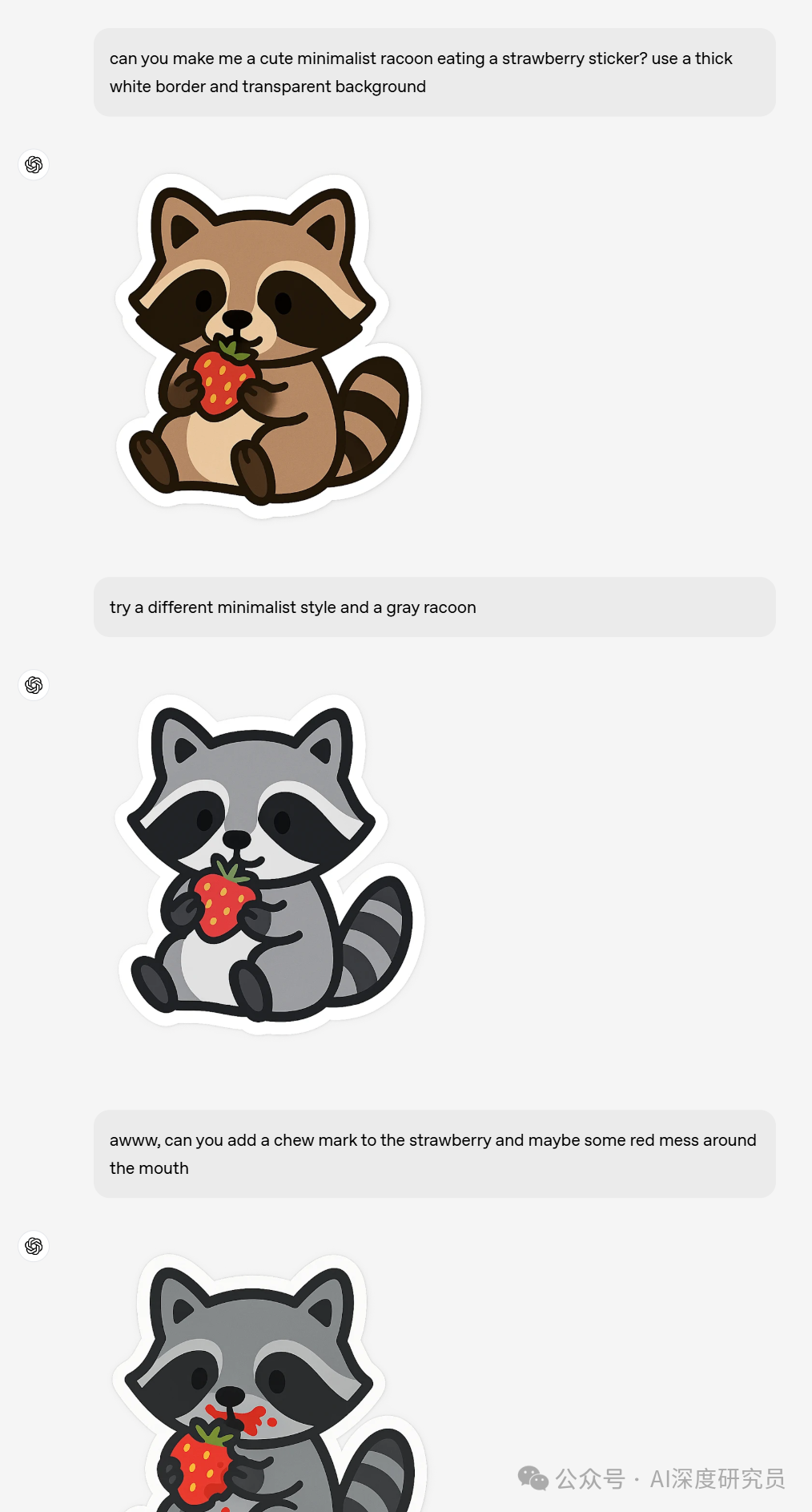
三、精准响应提示
GPT‑4o 的图像生成对提示指令响应精准,细节处理到位。相比之下,其他系统在处理 5 至 8 个物体时就已捉襟见肘,而 GPT‑4o 可轻松应对 10 至 20 个不同物体的复杂场景。得益于对物体属性与相互关系的更强绑定,用户能够更好地掌控生成图像的结构与内容。
提示词: A square image containing a 4 row by 4 column grid containing 16 objects on a white background. Go from left to right, top to bottom. Here's the list:
-
a blue star -
red triangle -
green square -
pink circle -
orange hourglass -
purple infinity sign -
black and white polka dot bowtie -
tiedye "42" -
an orange cat wearing a black baseball cap -
a map with a treasure chest -
a pair of googly eyes -
a thumbs up emoji -
a pair of scissors -
a blue and white giraffe -
the word "OpenAI" written in cursive -
a rainbow-colored lightning bolt

提示词: Times Square in New York City in the afternoon, with no people, vehicles, or illuminated billboards.

四、上下文理解能力
GPT‑4o 可读取并理解用户上传的图像,将其细节融入当前对话背景,在生成图像时做到有据可依、贴合语境。

五、融合世界知识
借助原生图像生成,GPT‑4o 能将其在文本与图像两方面的理解无缝连接,展现出更聪明、更高效的表现力。
提示词: Make me a professionally shot photorealistic diagram of the top selling cocktails in my bar with recipes labeled on each drink.
put the recipes on handwritten cards in front of each drink.
the cards are brown, and the text is black.
background is white
Title is "4 most popular cocktails"

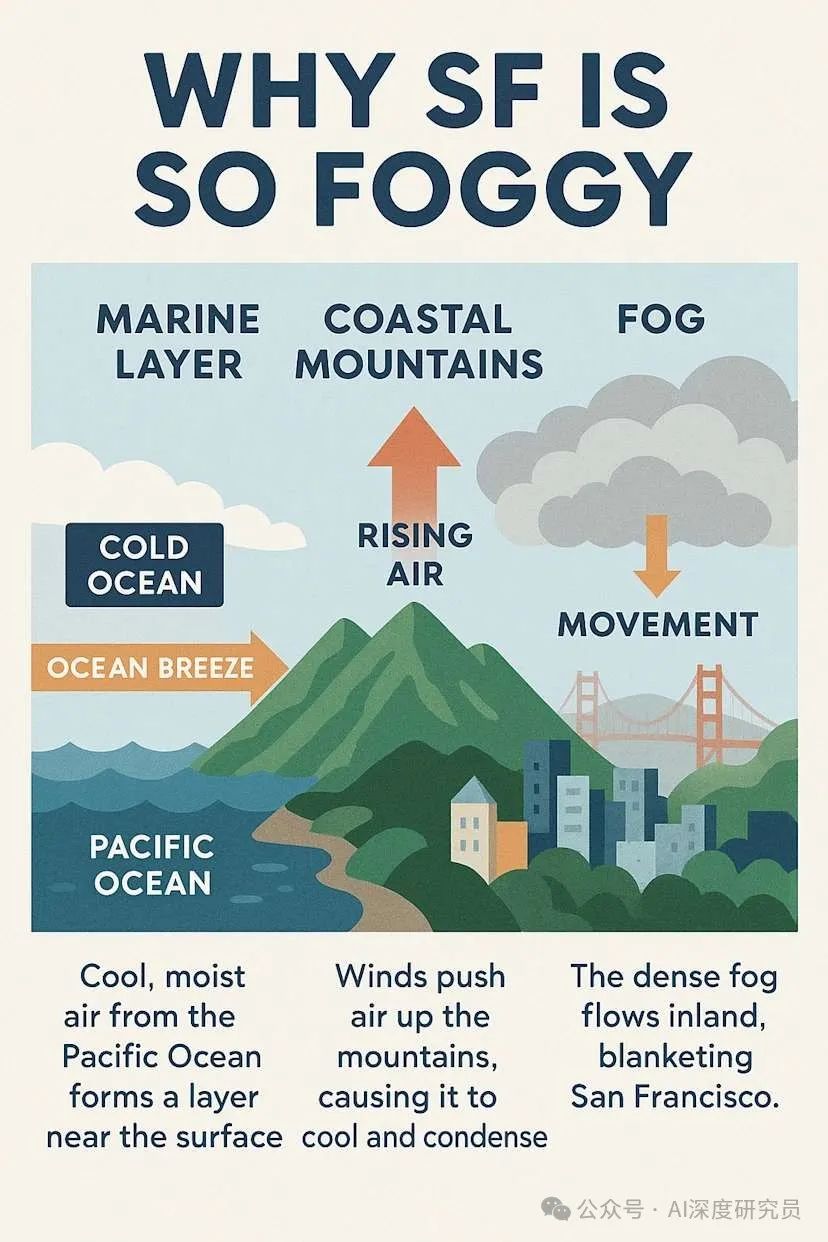
提示词: make a visual infographic describing why SF is so foggy
六、逼真表现与风格适配
模型在多种图像风格的训练数据上进行学习,因此能自然生成或转换图像,既真实又具风格多样性。
提示词: A candid paparazzi-style photo of Karl Marx hurriedly walking through the parking lot of the Mall of America, glancing over his shoulder with a startled expression as he tries to avoid being photographed. He’s clutching multiple glossy shopping bags filled with luxury goods. His coat flutters behind him in the wind, and one of the bags is swinging as if he’s mid-stride. Blurred background with cars and a glowing mall entrance to emphasize motion. Flash glare from the camera partially overexposes the image, giving it a chaotic, tabloid feel.

提示词: Best of 1 | Generate an portrait ad on a solid pastel background.
In solid white san serif text, "ChatGPT image generation" in the top left, about a third of the way down.
In solid white san serif text, "Form follows function", in the bottom right, about a third of the way up.
In the background, put a photo of a really sleek, modern sculpture. It should gradually transition from a wireframe sketch on the left to the fully photorealistic version on the right.
At the very bottom, in medium-small text, say "This entire poster was generated by ChatGPT image generation."

七、模型当前局限
尽管 GPT‑4o 图像生成功能实现了重大突破,但我们也清楚它仍存在不少值得关注的限制,这些问题将在未来的模型迭代中逐步解决。主要包括:
-
图像裁剪问题:在构图边缘或内容密集时,模型容易误剪掉关键元素,影响整体效果。
-
生成幻觉:有时模型会凭空“想象”出不存在的细节或物体,出现不符合现实的图像内容。
-
对象属性错配:当指令中涉及多个对象及其属性组合时,模型可能出现物体与特征对应混乱的问题。
-
图表生成不够精准:在绘制结构清晰、数据要求严格的图表时,输出可能出现误差或比例不一致。
-
多语言文本表现力有限:虽然支持非英语文字生成,但在图像中呈现如中文、阿拉伯文等语言时,有时会出现排版错乱或字符变形。
-
图像编辑控制不足:模型在修改或重绘图像细节方面的精确性仍有提升空间,尤其在精细区域。
-
小字体信息表达受限:图像中如需展示密集文本或小字号信息,容易出现模糊、重叠、无法辨识等问题。
八、访问方式与开放进度
从今天起,GPT‑4o 图像生成功能将在 ChatGPT 中全面上线,成为默认图像生成工具,率先开放给 Plus、Pro、Team 和免费用户使用,Enterprise 企业版和 Edu 教育版用户也将在不久之后陆续获得访问权限。此外,这项功能也已集成进 Sora。若你仍偏爱 DALL·E,也无需担心——它依然可以通过专属的 DALL·E GPT 使用。
开发者将在未来几周内,通过 API 接入 GPT‑4o 进行图像生成。
使用 GPT‑4o 生成和定制图像非常便捷,就像和它聊天一样自然——只需描述你想要的内容,包括画面比例、具体色值(如 hex 色码),或是否需要透明背景等细节。由于模型输出更为细腻,生成过程相对耗时,通常需要约一分钟完成。
原文链接:https://openai.com/index/introducing-4o-image-generation/
来源:官方媒体/网络新闻
转自:AI深度研究员


