在国家发展改革委等部门《关于促进数据产业高质量发展的指导意见》的指引下,数据要素作为新型生产要素,已成为推动经济社会高质量发展的核心引擎。春节期间爆火的DeepSeek,通过创新的工程手段与包容的开源生态,为数据产业高质量发展带来了新的思路。
DeepSeek-V3、DeepSeek-R1-Zero与DeepSeek-R1系列模型全面开源,支持开发者零成本调用与二次开发,助力中小企业快速构建智能应用,推动数据应用生态繁荣。此外,DeepSeek通过MLA+MOE+MTP架构创新、HAI-LLM训练框架和各类工程上的训练优化技术大幅降低了训练成本以及后续部署的推理成本。而模型蒸馏技术将大模型能力下沉至轻量化架构,显著降低对高性能算力的依赖。Deepseek采用了更为底层的PTX技术部分绕过了CUDA技术的限制实现了更快速的数据通信。而国产芯片如昇腾、沐曦、天数智芯等均能快速支持DeepSeek的部署,且在实际推理应用中与英伟达GPU推理效果无显著结果差异,为国产算力生态的崛起提供了重要支撑。
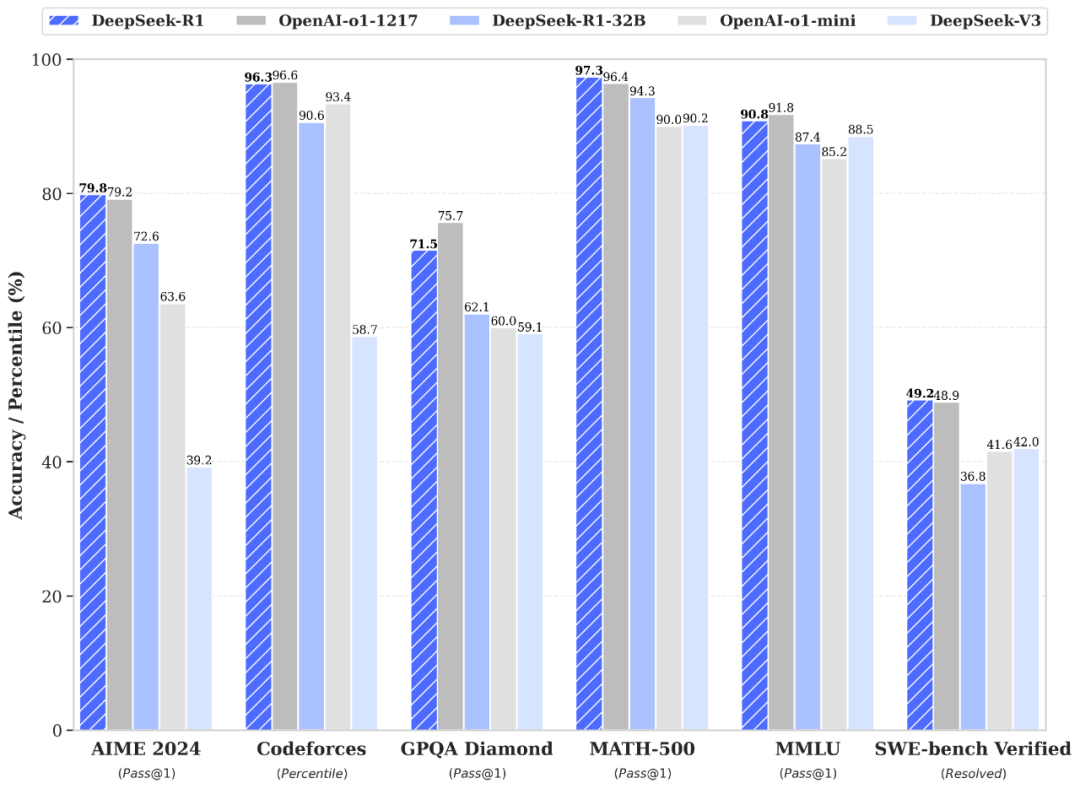
DeepSeek-R1在推理任务中表现优异,在数学、代码、自然科学等指标达到国际领先水平。
【1】DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
“旧时王谢堂前燕,飞入寻常百姓家”
/生态位足够强
在美国,OpenAI的出现被称为AI界的“iPhone时刻”。2023-2024年,国产大模型的竞争此消彼长,但主要受众仍集中在G端(政府)和B端(企业)信息化领域,中国AI界的“iPhone时刻”尚未到来。然而,2025年DeepSeek的爆红,标志着这一时刻的降临。上至耄耋老人,下至龆龀孩童,均可通过DeepSeek享受AI平权带来的技术红利。广阔的C端市场藉此打开,为AI智能体应用的爆发奠定了深厚的基础。
DeepSeek在数据工程方面主要有两个亮点:一是聚焦于强化学习数据,二是打造了强化学习阶段高质量数据生产线。
1. DeepSeek-R1-Zero聚焦强化学习数据价值
笔者曾在某地数据局交流研讨会上对人工智能高质量数据集按大模型全生命周期进行过划分:模型训练阶段数据、模型推理阶段数据、模型优化阶段数据。在模型训练阶段,训练数据又可分为通用预训练数据、增量预训练数据、微调数据与强化学习数据。在Scalling Law的加持下,大模型传统训练数据传统配置策略多采用预训练数据+微调数据的策略,以期通过“大力出奇迹”的方式,显著提升模型性能。
DeepSeek采用了与Scalling Law相反的策略,不依赖监督数据(Supervised Data),而直接将强化学习数据应用于基础模型,在规则驱动的奖励机制(格式奖励+准确性奖励)下,DeepSeek-R1-Zero强推理模型应运而生。
2. DeepSeek-R1打造强化学习阶段高质量数据生产线
为了提升DeepSeek-R1-Zero的泛化能力,DeepSeek-R1运用冷启动策略,融合面向推理的强化学习数据、全场景CoT&SFT数据、全场景强化学习数据,打造了一套SFT&RL高质量训练数据生产线,从而孕育出R1这一具有高度泛化能力的模型。
此外,DeepSeek-R1也展现出了非常优雅的数据工程能力,为强化学习数据策略提供了样板间:
在 2.2.3. Training Template部分,DeepSeek-R1通过简洁明了的模板设计,指导模型生成推理过程和最终答案。这种设计允许观察模型在强化学习过程中的自然进化,而不受内容偏见的影响。
 【2】DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
在2.3.2 Reasoning-oriented Reinforcement Learning部分,DeepSeek-R1运用了同R1-Zero相同的强化学习模式。在推理数据部分,R1聚焦于推理密集型数据(Reasoning-Intensive),包括代码、数学、科学、逻辑推理,数据由精心设计的问题与清晰完备的解决方案构成,旨在提高模型的推理释义能力。
在2.3.3. Rejection Sampling and Supervised Fine-Tuning部分,DeepSeek使用RL收敛后的检查点收集SFT数据,以增强模型在写作、角色扮演和其他通用任务上的能力。DeepSeek收集了大约600k的推理相关训练样本和200k的非推理训练样本。数据配比约3:1。
综上所述,DeepSeek证明了数据规模发展到一定程度时,后训练时代,推理数据将成为模型优劣的胜负手。其中,数据分布和数据质量成为高质量人工智能训练数据集的关键因素。
【2】DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
在2.3.2 Reasoning-oriented Reinforcement Learning部分,DeepSeek-R1运用了同R1-Zero相同的强化学习模式。在推理数据部分,R1聚焦于推理密集型数据(Reasoning-Intensive),包括代码、数学、科学、逻辑推理,数据由精心设计的问题与清晰完备的解决方案构成,旨在提高模型的推理释义能力。
在2.3.3. Rejection Sampling and Supervised Fine-Tuning部分,DeepSeek使用RL收敛后的检查点收集SFT数据,以增强模型在写作、角色扮演和其他通用任务上的能力。DeepSeek收集了大约600k的推理相关训练样本和200k的非推理训练样本。数据配比约3:1。
综上所述,DeepSeek证明了数据规模发展到一定程度时,后训练时代,推理数据将成为模型优劣的胜负手。其中,数据分布和数据质量成为高质量人工智能训练数据集的关键因素。
国家数据局在《关于促进数据产业高质量发展的指导意见》(以下简称“《指导意见》”)中提出要促进产业链协同发展,DeepSeek通过开放模型能力,吸引算力供应商、行业数据方与应用开发者共建轻量化协作网络,破解传统产业“数据孤岛”与“场景碎片化”难题,推动数据要素从低效分散向规模化、价值化跃升。
2. 以轻量化、高性能保障AI Agent数据应用市场繁荣
随着2025年AI Agent元年的到来,DeepSeek凭借其轻量化部署要求、高性能推理能力,可将技术门槛降至“业务专家+算法工程师+工程团队”的极简配置,赋能中小型企业快速构建行业智能体,将有效驱动教育、医疗、科研、文化等领域形成“数据-算法-场景”闭环,激活长尾市场创新活力。
《指导意见》提出加快数据技术创新,完善开源治理生态,支持建设数据技术开源平台和社区,引导激励企业深度参与社区运营。DeepSeek开源R1-Zero 和 R1 两个 660B 模型外,还蒸馏了6个小模型并开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果;此外,标准化的API接口将进一步推动“数据即服务(DaaS)”、“模型即服务(MaaS)”等新业态发展,加速数据资产向新质生产力转化。
第一,聚焦国产化技术攻坚,打造高可靠服务能力。融合一体化算力调度技术、稳定、高效的DeepSeek Serveless API将成为企业级应用的首选,为算力节点提供了可靠、稳定的消纳。
第二,强化数据与基准测试双轮驱动,夯实行业智能化根基。针对高质量训练数据要求,联合产学研机构共建垂直领域强化学习数据集与行业数据基准测试体系,聚焦推理数据,推动数据标注、过程推理与评估标准深度融合,构建以数据为中心的人工智能产业发展体系。
第三,加速智能体规模化落地,释放数据要素乘数效应。以“数据要素×”三年行动为指引,加快全域数字化转型,聚焦教育、医疗、科研、文化等高价值场景,研发行业智能体解决方案,通过流程重构与知识沉淀实现决策闭环,助力传统产业向“数据驱动型”跃迁,加速形成轻量化、高价值、可复用的行业智能应用范式。
第四,构建“AI+X”人才生态闭环,筑牢可持续发展底座。联合高校与龙头企业,完善跨学科课程体系与实训平台,培育兼具AI技术能力与行业认知的复合型人才;同时通过开源社区、开发者生态与行业联盟联动,形成“技术迭代-应用反馈-人才培养”的正向循环,为数据产业高质量发展注入核心动能。
展望2025年,是数据产业高质量发展关键之年,是AI Agent应用井喷之年。海新域城市更新集团将持续整合多元场景应用,助力海淀区数据要素和人工智能产业高质量发展。
来源:海新域城市更新集团公众号,作者:产业研究院 王吴越






 【2】DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
【2】DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning


